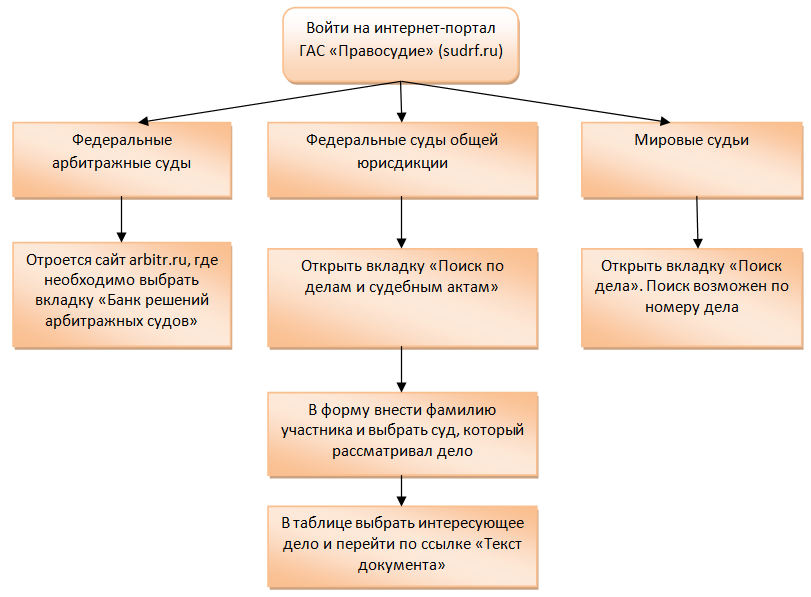
Big data
Содержание:
- Какие компании занимаются большими данными
- Карта пешеходных маршрутов
- Анализ производительности запросов в ClickHouse. Доклад Яндекса
- Сколько стоят ваши социальные данные?
- Онлайн-кассы как эталонный источник больших данных
- Математическое расследование, как подделывали выборы губернатора в Приморье 16 сентября 2018 года
- Данные нужно собирать в одном месте
- Большие данные с чужих онлайн-касс позволяют вести подбор места для бизнеса
- Рынок Big data в России
- Источники больших данных
- Чем занимается девопс-инженер в проектах Big Data и не только
- Big Data нужна всем
- Три больших кита Big Data
- Примеры задач, эффективно решаемых при помощи MapReduce
- Будущее Big Data: аналитика и управление данными
- Эластичный MapReduce. Распределенная реализация
- Кто использует большие данные
- Профессиональные направления в мире Big Data
- Бизнес-аналитика в управлении рисками: Некоторые последние достижения (2014 год)
Какие компании занимаются большими данными
Первыми с большими данными, либо с «биг дата», начали работать сотовые операторы и поисковые системы. У поисковиков становилось все больше и больше запросов, а текст тяжелее, чем цифры. На работу с абзацем текста уходит больше времени, чем с финансовой транзакцией. Пользователь ждет, что поисковик отработает запрос за долю секунды — недопустимо, чтобы он работал даже полминуты. Поэтому поисковики первые начали работать с распараллеливанием при работе с данными.
Чуть позже подключились различные финансовые организации и ритейл. Сами транзакции у них не такие объемные, но большие данные появляются за счет того, что транзакций очень много.
Количество данных растет вообще у всех. Например, у банков и раньше было много данных, но для них не всегда требовались принципы работы, как с большими. Затем банки стали больше работать с данными клиентов. Стали придумывать более гибкие вклады, кредиты, разные тарифы, стали плотнее анализировать транзакции. Для этого уже требовались быстрые способы работы.
Сейчас банки хотят анализировать не только внутреннюю информацию, но и стороннюю. Они хотят получать большие данные от того же ритейла, хотят знать, на что человек тратит деньги. На основе этой информации они пытаются делать коммерческие предложения.
Сейчас вся информация связывается между собой. Ритейлу, банкам, операторам связи и даже поисковикам — всем теперь интересны данные друг друга.
Карта пешеходных маршрутов
Магазин типа «Пятёрочки» надо открывать там, где ходят люди. Никто специально не поедет в соседний район ради продуктового магазина, поэтому для начала нужно ответить на такие вопросы:
Где в этом районе ходят люди?
По каким маршрутам?
Сколько их в разное время?
А где точно не ходят?
Чтобы это узнать, можно воспользоваться биг-датой: собрать её или заполучить. Примеры:
У сотового оператора. Можно получить информацию о геопозиции устройств и их примерном перемещении у оператора сотовой связи. Это обезличенные данные без привязки к фамилии или номеру: только информация о пути передвижения устройств в конкретном районе. Это дорого, но эффективно.
Данные собираются с сотовых базовых станций — это устройства, к которым подключаются ваши телефоны, чтобы быть на связи. В городах базовые станции стоят довольно плотно, и по уровню сигнала с них можно довольно точно определить положение всех ближайших абонентов.
Поставить Wi-Fi- и Bluetooth-точки в разных местах нужного района. Они соберут информацию о проходящих мимо людях через их же телефоны. Принцип такой: точка сканирует пространство и ищет мобильники с включённым вайфаем. Как только нашла — начинает его отслеживать до тех пор, пока человек не выйдет из зоны действия. При достаточном количестве таких точек можно получить довольно неплохую карту перемещений.
Поставить камеры с распознаванием лиц. Тут всё относительно просто — располагаем камеры в автомобилях или на зданиях, запоминаем лицо каждого проходящего и путь, по которому он прошёл. Потом накладываем это на карту местности и получаем пешеходные маршруты. Распознавание лиц уже настолько распространённая технология, что это может сделать кто угодно.
После того как мы получили карту перемещений, её нужно проанализировать и найти те точки, где получается максимальная проходимость. В идеале — найти такие места, где пешеходный поток не заходит в магазины конкурентов или где их вообще нет. Для этого просто собираем статистические данные, совмещаем их с картами и используем аналитические приёмы, чтобы сделать выводы.
Анализ производительности запросов в ClickHouse. Доклад Яндекса
Что делать, если ваш запрос к базе выполняется недостаточно быстро? Как узнать, оптимально ли запрос использует вычислительные ресурсы или его можно ускорить? На последней конференции HighLoad++ в Москве я рассказал об интроспекции производительности запросов — и о том, что даёт СУБД ClickHouse, и о возможностях ОС, которые должны быть известны каждому.
Каждый раз, когда я делаю запрос, меня волнует не только результат, но и то, что этот запрос делает. Например, он работает одну секунду. Много это или мало? Я всегда думаю: а почему не полсекунды? Потом что-нибудь оптимизирую, ускоряю, и он работает 10 мс. Обычно я доволен. Но все-таки я стараюсь в этом случае сделать недовольное выражение лица и спросить: «Почему не 5 мс?» Как можно выяснить, на что тратится время при обработке запроса? Можно ли его в принципе ускорить?
Сколько стоят ваши социальные данные?
Человек — это то, что он потребляет. Данное высказывание в современном мире теперь относится не только к еде. Человек жив благодаря не только хлебу насущному. Мы каждый день потребляем гигабайты информации, за один день мы перерабатываем её столько, сколько в средние века люди не получали и за всю жизнь. Только проснулись и сразу проверяем уведомления электронной почты, пока завтракаем пролистываем ленту вКонтакте или любой другой соцсети, в свободное время время смотрим ролики на YouTube и т.д. и т.п. Этими действиями мы не только потребляем, но и создаем информацию. Каждый наш шаг в Интернете, любой наш клик, все перемещения из сайта в сайт фиксируются и записываются. Это называется социальными данными пользователя. Именно они составляют нашу виртуальную личность. И у этой нашей с вами личности есть своя цена, за которую готовы платить большие деньги.
Онлайн-кассы как эталонный источник больших данных
Онлайн-касса — это с виду обыкновенный кассовый аппарат, формирующий чеки для выдачи покупателям в целях подтверждения оплаты. Но это далеко не только так: соответствующий инновационный тип ККТ формирует очень емкую подборку данных — «фискальные данные». Которые в цифровом и удобном для обработки (стандартизованном — в соответствии с принятыми форматами) виде могут аккумулироваться различными заинтересованными сторонами.
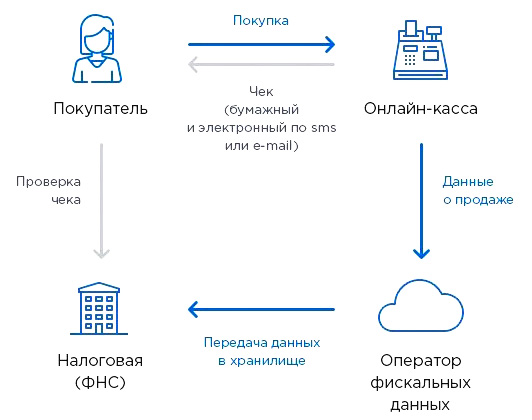
Например — ФНС, которой интересны выручка и расходы торгового предприятия как налогоплательщика. Налоговая получает эти данные с онлайн-касс автоматически, хочет этого магазин или нет: все онлайн-кассы по закону передают сведения в ФНС через интернет.
Например — Оператор фискальных данных, обязательный по закону же посредник между предприятием и ФНС. Именно ОФД «собирает» данные с онлайн-касс, преобразовывает в нужный формат и направляет налоговикам. По пути — в законном же порядке, «обрабатывает» их, не нарушая ничьих интересов.
И на основании этой обработки (которую может при желании делать и ФНС тоже — как и иное любое заинтересованное лицо, у кого, разумеется, есть доступ к фискальным данным) ОФД может вырабатывать прогнозы и предикативные данные — в интересах бизнеса.
В фискальные данные входит куча информации. Это не только выручка, но и, к примеру, состав каждого чека — буквально по единичной бутылке. Полный перечень реквизитов фискального чека можно почитать, заглянув в статью 4.7 Закона № 54-ФЗ (), который регулирует применение контрольно-кассовой техники. И можно увидеть, что в этих реквизитах много чего интересного.
На основании фискальных данных с одного кассового аппарата можно отследить, почем и кем (на каком месте) была продана одна бутылка (пусть минеральной воды определенного бренда). Это «просто данные», simple, если угодно, data. На основании фискальных данных (ФД) с миллиона кассовых аппаратов — обстоятельства продажи миллиона бутылок. А если представить, что разных брендов? Это уже «большие данные», Big Data.
И совершенно очевидно, что анализ данных «по бутылкам» — это совершенно незначительная область обработки Big Data по фискальным данным. Это огромный, попросту невообразимо огромный ресурс. Еще недавно недоступный бизнесу. А сегодня — способный дать заинтересованному лицу крутейшие конкурентные преимущества.
Практические инструменты для извлечения такого преимущества уже есть — ознакомимся с ними далее.
Математическое расследование, как подделывали выборы губернатора в Приморье 16 сентября 2018 года
Во втором туре выборов губернатора Приморского края 16 сентября 2018 года встречались действующий и.о. губернатора Андрей Тарасенко и занявший второе место в первом туре коммунист Андрей Ищенко. В ходе подсчета голосов на сайте ЦИК РФ отображалась информационная панель с растущим числом обработанных протоколов и голосов за кандидатов.
Публикация подробных данных по участкам на официальном сайте ЦИК www.izbirkom.ru замерла после ввода 1484 (95.74%) протоколов и не возобновлялась до самого конца. Поэтому когда в трансляции лидер голосования вдруг поменялся с Ищенко на Тарасенко, было неясно, как именно это могло произойти. В СМИ просто писали «после обработки 99,03% протоколов лидер сменился».
Однако, располагая промежуточными суммарными данными из информационной панели, с помощью простой математики и программирования можно подробно установить, что именно происходило с протоколами в ночь после выборов. Используем Python, Colab от Google и Z3 theorem prover от Microsoft Research. Ну и добьём всё обычной дедукцией.
Данные нужно собирать в одном месте
Необходимость обучения алгоритмов ведет к тому, что появляются компании и сервисы, которые агрегируют данные в одном месте. Это может вызвать проблемы с безопасностью и доступом к пользовательской информации.
Агрегация данных для обучения искусственного интеллекта, алгоритмов и машин уже перестала быть настолько важной, как прежде. Сейчас корпорации, такие как Google и Apple, активно работают над тем, чтобы сделать свои устройства частью распределенной сети машинного обучения
Google по своим устройствам имеет одну сеть, которая работает одновременно. Apple идет по его стопам в области новых технологий на основе больших данных. Например, в патенте Google «Federated Learning» все построено на распределенном обучении. Данные с телефона не утекают в определенный Data-центр, а приезжает модель, обучается и начинает коммуницировать с другими моделями мобильных телефонов или через общий хаб. Таким образом сохраняется приватность.
Модель — это алгоритм, который может быть сложным или простым, но на выходе будет получен ответ на интересующий нас вопрос. Его можно задать математически формулами или словами. В принципе, даже наши юридические законы — это модель, которая позволяет классифицировать действия человека на приемлемые (ненаказуемые) и неприемлемые (наказуемые).
Моделью может быть набор формул для описания физического феномена, а могут быть правила языка, делящие многообразия слов и словосочетаний на корректные (грамотные) и некорректные (безграмотные). Если обобщить, не прибегая к строгим математическим формулировкам, то модель — это формализуемый критерий, который мы получаем на основе тренировки на имеющихся данных.
Большие данные с чужих онлайн-касс позволяют вести подбор места для бизнеса
Еще один сервис от ОФД.ру – продукт (подбор помещения для открытия новой торговой точки и прогнозирование выручки).

Он позволяет, таким образом, определить — насколько может быть эффективным предполагаемое место открытия магазина, аптеки, любой точки продаж или оказания услуг. Спрогнозировать эту эффективность. Аналитика также строится по данным Big Data, что находятся в распоряжении Оператора.
При этом, оцениваются точки, реально доступные на рынке — выставленные на продажу или сдаваемые в аренду. Можно подобрать до 5 точек — в которых бизнес может быть максимально эффективным.
По каждому помещению показывается прогноз в части выручки — с учетом особенностей потребительского поведения, деятельности конкурентов и инфраструктуры. В расчет берутся даже типичные пешеходные маршруты: движение людей по ним тоже может играть роль (и формировать определенный процент Big Data).
И здесь, понятно, анализ фискальных данных может и не играть ключевой роли. Но они, опять же, почти наверняка, задействуются — с учетом их надежности и информативности.
Ходьбы людей по маршрутам онлайн-кассы, конечно, не отслеживают. Но косвенно позволяют «смоделировать» их перемещение по городу: например, если одна касса ОФД «покажет», что человек был в продуктовом магазине и основательно там закупился, а другая — отразит факт покупки человеком билета в автобусе на определенном маршруте через несколько минут, то будет очевидно, что человек пошел от выхода магазина к остановке соответствующего автобуса по кратчайшему пути. И никуда в сторону не отходил: в руках — полные пакеты и надо поскорее отнести их домой.
Не фантастика — но технология совершенно инновационная, уникальная и конкурентность образующая. И доступная почти всем желающим — в том числе самым малым бизнесам. Никаких «спутников-шпионов» и скрытых камер: все легально и тактично.
И актуально: данные по Big Data могут (и должны — это, к слову, один из критериев «больших данных») анализироваться в реальном времени. Московский метрополитен может открыть очередную станцию — и не исключено, что она окажется рядом с магазином. Тогда человек пойдет не на автобус, а на метро — что немедленно покажется в аналитике, «типичный» пешеходный маршрут заметно откорректируется.
Прогнозировать выручку и прочие показатели бизнеса умеют и многие конкуренты — например, «Платформа ОФД». Оценивать эффективность бизнеса на определенном месте — тоже. В числе компаний, специализирующихся на этом — «Первый ОФД». В целом, все операторы имеют здесь сопоставимые возможности — и пользователю их сервисов надо просто подобрать оптимальное решение для себя. Смело пробовать разные варианты и выбирать лучший.
Рынок Big data в России
В 2017 году мировой доход на рынке big data должен достигнуть $150,8 млрд, что на 12,4% больше, чем в прошлом году. В мировом масштабе российский рынок услуг и технологий big data ещё очень мал. В 2014 году американская компания IDC оценивала его в $340 млн. В России технологию используют в банковской сфере, энергетике, логистике, государственном секторе, телекоме и промышленности.
Что касается рынка данных, он в России только зарождается. Внутри экосистемы RTB поставщиками данных выступают владельцы программатик-платформ управления данными (DMP) и бирж данных (data exchange). Телеком-операторы в пилотном режиме делятся с банками потребительской информацией о потенциальных заёмщиках.
|
15 сентября в Москве состоится конференция по большим данным Big Data Conference. В программе — бизнес-кейсы, технические решения и научные достижения лучших специалистов в этой области. Приглашаем всех, кто заинтересован в работе с большими данными и хочет их применять в реальном бизнесе. |
Обычно большие данные поступают из трёх источников:
- Интернет (соцсети, форумы, блоги, СМИ и другие сайты);
- Корпоративные архивы документов;
- Показания датчиков, приборов и других устройств.
Источники больших данных
В качестве примера типичного источника больших данных можно привести социальные сети – каждый профиль или публичная страница представляет собой одну маленькую каплю в никак не структурированном океане информации. Причем независимо от количества хранящихся в том или ином профиле сведений взаимодействие с каждым из пользователей должно быть максимально быстрым.
Большие данные непрерывно накапливаются практически в любой сфере человеческой жизни. Сюда входит любая отрасль, связанная либо с человеческими взаимодействиями, либо с вычислениями. Это и социальные медиа, и медицина, и банковская сфера, а также системы устройств, получающие многочисленные результаты ежедневных вычислений. Например, астрономические наблюдения, метеорологические сведения и информация с устройств зондирования Земли.
Информация со всевозможных систем слежения в режиме реального времени также поступает на сервера той или иной компании. Телевидение и радиовещание, базы звонков операторов сотовой связи – взаимодействие каждого конкретного человека с ними минимально, но в совокупности вся эта информация становится большими данными.
Технологии больших данных стали неотъемлемыми от научно-исследовательской деятельности и коммерции. Более того, они начинают захватывать и сферу государственного управления – и везде требуется внедрение все более эффективных систем хранения и манипулирования информацией.
Чем занимается девопс-инженер в проектах Big Data и не только
Можно сказать, что DevOps-инженер синхронизирует все этапы создания программного продукта: от разработки кода до эксплуатации, автоматизируя задачи непрерывного тестирования, развертывания и администрирования приложения с помощью технологий контейнеризации (Kubernetes, Docker, Rocket), виртуализации (Vagrant), интеграции (Jenkins) управления инфраструктурой как кодом (Puppet) и постоянного мониторинга производительности продукта .
Прикладные сферы девопс-инженера
При этом навыки администрирования локальных и облачных серверов становятся особенно важными в Big Data проектах, поскольку информация хранится и обрабатывается в Hadoop-кластерах. Такой широкий круг задач предполагает высокий уровень компетентности девопс-инженера: наличие специальных знаний и профессионального опыта в процессах разработки (включая тестирование) и эксплуатации. Это соответствует Т-образной модели компетенций, которая реализуется в Agile-командах, где каждый участник обладает обширным кругозором и набором умений, являясь экспертом в одной прикладной области [4. Таким образом, если Data Scientist обладает навыками развертывания решения в промышленную эксплуатацию (production) и администрирования экосистемы Hadoop, это не отменяет необходимость присутствия DevOps-инженера в проектной команде. Однако, существенно облегчает эффективное взаимодействие в Big Data проекте специалистов разных профилей, которых мы рассмотрим в отдельной статье.

Девопс – это человек-оркестр с большим набором ИТ-компетенций
Big Data нужна всем
Есть области знаний, где нам приходится сталкиваться с большим количеством данных для обработки. Но не всегда Big Data дают ощутимый результат.
Компания Gartner провела исследования, какие кейсы наиболее популярны в различных индустриях. Все данные были представлены в виде тепловой карты кейсов, реализованных в бизнесе. Чем краснее квадратик (чем больше процент), тем больше из опрошенных компаний реализовали кейсы на основе Big Data у себя в бизнесе.

Как видно из исследования, больше всех кейсов было реализовано в области маркетинга, таргетирования и customer experience. То есть в самой актуальной области клиентской аналитики и работы с клиентами — в сфере продаж b2c. Меньше всего кейсов реализовали в государственном секторе, но область эффективности процессов для этого сектора наиболее актуальна. Сфера новых продуктов пока остается для этого сектора несущественной.
А вот такой опрос проводил Tech Pro Research:

Интересно, что в области образования и здравоохранения большие данные оказались не так популярны. А вот финансовые и государственные структуры, инжиниринг и ИТ активно пользуются этими методами. Причем телеком самая популярная сфера для внедрения технологий Big Data.
Big Data не нужны, если в вашей компании:
- сотрудники в состоянии обработать и автоматизировать данные по клиентам с помощью обычных CRM-систем;
- планирование, учет и контроль бизнес-процессов вполне реализуем с помощью ERP-систем;
- раньше объединяли данные из различных источников информации, обрабатывали их, оценивали полученный результат с помощью BI-систем и не испытывали со всем вышеперечисленным никаких трудностей.
Три больших кита Big Data
Когда мы говорим о больших данных, мы не можем не упомянуть три ключевых свойства: объем, скорость и разнообразие. Эти три вектора позволяют нам понять, чем большие данные выгодно отличаются от управления данными старой школы.
Объем
Количество данных должно быть достаточно. Вам придется обрабатывать огромные объемы неструктурированных данных с низкой плотностью. И размер данных является наиболее важным показателем при определении возможной извлекаемой ценности, так как чем больше данных, тем точнее можно получить результат на них. Клики-потоки, системные журналы и системы потоковой обработки обычно генерируют достаточные по объему данные.
Разнообразие
Давно прошли те времена, когда данные собирались из одного места и возвращались в едином формате. Сегодня данные бывают всех форм и размеров, включая видео, текст, звук, графику и даже выкалывание на бумаге. Таким образом, большие данные предоставляют возможности для использования новых и существующих данных и разработки новых способов сбора данных в будущем.
Скорость
Под скоростью обычное подразумевается, как быстро данные попадают к нам из различных систем для дальнейшего с ними взаимодействия. Некоторые данные могут появляться в режиме реального времени, а некоторые поступают пачками
Поскольку большинство платформ обрабатывают входящие данные с разной скоростью, важно не ускорять процесс принятия решения, не имея всей необходимой информации
Примеры задач, эффективно решаемых при помощи MapReduce
Word Count
Начнём с классической задачи – Word Count. Задача формулируется следующим образом: имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося в корпусе, посчитать суммарное количество раз, которое оно встретилось в корпусе.
Решение:
Раз имеем большой корпус документов – пусть один документ будет одной входной записью для MapRreduce–задачи. В MapReduce мы можем только задавать пользовательские функции, что мы и сделаем (будем использовать python-like псевдокод):
Функция map превращает входной документ в набор пар (слово, 1), shuffle прозрачно для нас превращает это в пары (слово, ), reduce суммирует эти единички, возвращая финальный ответ для слова.
Обработка логов рекламной системы
Задача: имеется csv-лог рекламной системы вида:
Решение:
Функция map проверяет, нужна ли нам данная запись – и если нужна, оставляет только нужную информацию (город и размер платежа). Функция reduce вычисляет финальный ответ по городу, имея список всех платежей в этом городе.
Будущее Big Data: аналитика и управление данными
Интересно также отметить, что аналитики Gartner составили отдельный прогноз по наиболее перспективным технологиям в области управления данными (Data Management), разделяя сферу Big Data от искусственного интеллекта. В частности, согласно этому исследованию, сейчас на пике завышенных ожиданий находятся следующие технологии управления данными :
- Data Fabric – фабрики данных, о которых мы рассказываем здесь;
- Data Hub Strategy – стратегические хабы данных;
- Data Catalog – каталоги данных;
- Data Classification – классификация данных;
- File Analysis – файловой анализ;
- Time Series DBMS – СУБД временных рядов;
- Augmented Transactions – расширенные транзакции;
- Event Stream Processing – потоковая обработка событий, например, использованием таких Big Data инструментов, как Apache Kafka, Spark, Storm, Flink и пр.
На этапе старта Gartner располагает концепцию DataOps, специальные СУБД для хранения бухгалтерских данных типа гроссбуха для биткоинов (Ledger DBMS), ML-инструменты поддержки качества данных (Machine Learning-Enabled Data Quality) и частные СУБД в виде облачных платформ (Private Cloud dbPaaS). Спад интереса отмечается к следующим технологиям :
- Augmented Data Management – расширенное управление данными;
- Data Preparation – подготовка данных (к машинному обучению и аналитике);
- SQL Interfaces to Cloud Object Stores – SQL-интерфейсы к облачным хранилищам;
- Multimodel DBMSs – мультимодельные СУБД;
- Master Data Management, Information Stewardship Applications и Application Data Management – приложения для управления данными;
- Metadata Management Solutions – решения для управления метаданными;
- Graph DBMSs – графовые СУБД;
- Blockchain – блокчейн;
- Data Lakes – озеро данных или корпоративное хранилище данных, например, на базе Apache Hadoop;
- Distributed Ledgers – распределенные кошелки для биткоинов и подобных криптовалют;
- Apache Spark.
Доверие общества восстанавливается к аналитическим СУБД (In-DBMS Analytics, Analytical In-Memory DBMS), SQL-интерфейсам к Apache Hadoop (например, Cloudera Impala, Apache Phoenix, Drill и Hive), логическим хранилищам данных (Logical Data Warehouse), колоночным и документо-ориентированным СУБД (Wide-Column DBMS и Document Store DBMS), инфраструктурным платформам и инструментам для интеграции данных (iPaaS for Data Integration и Data Integration Tools), а также к резидентным базам данных (Operational In-Memory DBMS), которые размещаются в оперативной памяти. Наконец, на плато продуктивности сегодня находятся различные системы миграции контента (Content Migration), криптографические СУБД (Database Encryption), виртуализация данных (Data Virtualization) и резидентные сетки данных (In-Memory Data Grids) .
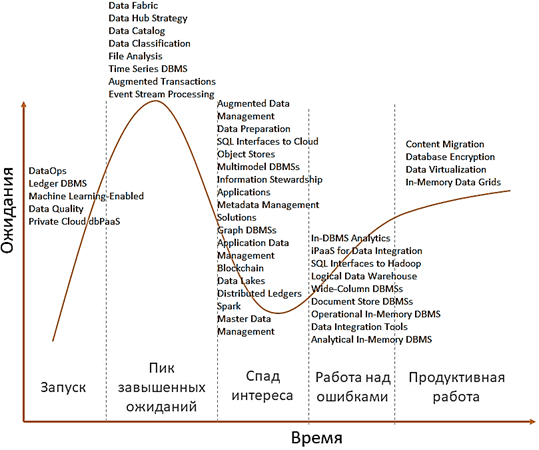
Самые перспективные технологии Big Data и другие приложения Data Management: аналитический прогноз Gartner 2019
На практике, по крайней мере, в России технологии управления данными только начинают входить в фазу интереса и востребованности. В частности, эту тенденцию подтверждает растущий спрос на DataOps-инженеров и государственный тренд на цифровизацию. Разговор о наиболее перспективных с точки зрения Gartner ИТ-тенденциях мы продолжим в следующий раз.
Как эффективно использовать эти и другие технологии больших данных, машинного обучения для цифровизации своего бизнеса, вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Аналитика больших данных для руководителей
Смотреть расписание
Записаться на курс
Источники
- https://ru.wikipedia.org/wiki/Gartner
- https://www.gartner.com/smarterwithgartner/top-trends-on-the-gartner-hype-cycle-for-artificial-intelligence-2019
- https://habr.com/ru/post/475032/
- https://www.gartner.com/en/documents/3955768/hype-cycle-for-data-management-2019
Эластичный MapReduce. Распределенная реализация
Так случилось, что первый посмотренный мною фильм с упоминанием слова «суперкомпьютер» был Терминатор. Но, как ни странно, моя (тогда еще) не сформировавшаяся психика не посчитала скайнет мировым злом, списав агрессивное поведение первого в мире ИИ на недостаточное покрытие юнит тестами.
На тот момент у меня был ZX Spectrum (чьих 128 Kb явно не хватало на запуск чего-то похожего на ИИ) и много (думаю лет 10) свободного времени. Благодаря последнему факту, я благополучно дождался эры виртуализации. Можно было снять хоть 10K VPS, установить между ними канал связи и начинать создавать ИИ. Но мне хотелось заниматься программированием, а не администрированием/конфигурацией grid-системы, и я разумно начал ждать, когда вычислительные ресурсы начнут предоставляться как сервис.
Моей радости не было конца, когда появились облачные сервисы. Но радость длилась недолго: стало понятно, что пока прямые коммуникации между отдельными вычислительными инстансами – это фантастика код, который нужно писать самому (то есть с большой вероятностью он работать не будет). Попереживав пару лет по этому поводу, я (мы все) дождался Hadoop, сначала «on-premises», а потом и эластичного «on-demand». Но и там, как оказалось, не всё так эластично гладко
Кто использует большие данные

Наибольший прогресс отрасли наблюдается в США и Европе. Вот крупнейшие иностранные компании и ведомства, которые используют Big Data:
• HSBC повышает безопасность клиентов пластиковых карт. Компания утверждает, что в 10 раз улучшила распознавание мошеннических операций и в 3 раза – защиту от мошенничества в целом.
• Суперкомпьютер Watson, разработанный IBM, анализирует финансовые транзакции в режиме реального времени. Это позволяет сократить частоту ложных срабатываний системы безопасности на 50% и выявить на 15% больше мошеннических действий.
• Procter&Gamble проводит с использованием Big Data маркетинговые исследования, более точно прогнозируя желания клиентов и спрос новых продуктов.
• Министерство труда Германии добивается целевого расхода средств, анализируя большие данные при обработке заявок на пособия. Это помогает направить деньги тем, кто действительно в них нуждается (оказалось, что 20% пособий выплачивались нецелесообразно). Министерство утверждает, что инструменты Big Data сокращают затраты на €10 млрд.
Среди российских компаний стоит отметить следующие:
• Яндекс. Это корпорация, которая управляет одним из самых популярных поисковиков и делает цифровые продукты едва ли не для каждой сферы жизни. Для Яндекс Big Data – не инновация, а обязанность, продиктованная собственными нуждами. В компании работают алгоритмы таргетинга рекламы, прогноза пробок, оптимизации поисковой выдачи, музыкальных рекомендаций, фильтрации спама.
• Мегафон
Телекоммуникационный гигант обратил внимание на большие данные примерно пять лет назад. Работа над геоаналитикой привела к созданию готовых решений анализа пассажироперевозок
В этой области у Мегафон есть сотрудничество с РЖД.
• Билайн. Этот мобильный оператор анализирует массивы информации для борьбы со спамом и мошенничеством, оптимизации линейки продуктов, прогнозирования проблем у клиентов. Известно, что корпорация сотрудничает с банками – оператор помогает анонимно оценивать кредитоспособность абонентов.
• Сбербанк. В крупнейшем банке России супермассивы анализируются для оптимизации затрат, грамотного управления рисками, борьбы с мошенничеством, а также расчёта премий и бонусов для сотрудников. Похожие задачи с помощью Big Data решают конкуренты: Альфа-банк, ВТБ24, Тинькофф-банк, Газпромбанк.
И за границей, и в России организации в основном пользуются сторонними разработками, а не создают инструменты для Big Data сами. В этой сфере популярны технологии Oracle, Teradata, SAS, Impala, Apache, Zettaset, IBM, Vowpal.
Читайте: Что такое интернет вещей, как он работает и чем полезен
Профессиональные направления в мире Big Data
Под термином «большие данные» скрывается множество понятий: от непосредственно самих информационных массивов до технологий по их сбору, обработке, анализу и хранению. Поэтому, прежде чем пытаться объять необъятное в стремлении изучить все, что относится к Big Data, выделим в этой области знаний следующие направления:
- инженерия – создание, настройка и поддержка программно-аппаратной инфраструктуры для систем сбора, обработки, аналитики и хранения информационных потоков и массивов, включая конфигурирование локальных и облачных кластеров. За эти процессы отвечают администратор и инженер Big Data. Чем отличается работа администратора больших данных от деятельности сисадмина, мы писали в этом материале. Какие именно навыки, знания и умения нужны специалистам по инженерии больших данных, а также сколько они за это получают, мы описываем в отдельных материалах.
На стыке вышеуказанных 2-х направлений находятся программист Big Data и DevOps-инженер, а также специалист по сопровождению жизненного цикла корпоративных данных (DataOps) и директор по данным (CDO, Chief Data Officer), который курирует на предприятии все вопросы, связанные с информацией. О роли каждого профессионала в Agile-команде мы немного рассказывали здесь.
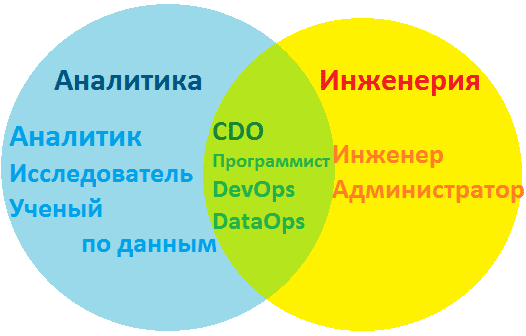
Профессиональные направления и специальности Big Data
Бизнес-аналитика в управлении рисками: Некоторые последние достижения (2014 год)
Перевод
На одном из интенсивов по BI-аналитике от коуча услышал высказывание: «BI-аналитика создает ценность для предприятия, но определить величину денежного эквивалента этой ценности невозможно».
Я не согласился с этим высказыванием так как, на мой взгляд, менеджмент создает систему метрик бизнес-аналитики с целью видеть векторы развития предприятия и скрытые проблемы, приводящие к снижению итоговых результатов. И если с помощью метрик вектора развития сложно конкретизировать, то кризисные явления идентифицируются достаточно надежно, при качественном исследовании исторических данных. То есть проявляется явная функция пространства метрик, показывающая зоны, в которые предприятию предпочтительно не попадать и система бизнес-метрик является инструментом риск-менеджмента. В настоящий момент технологии монетизации мероприятий риск-менеджмента хорошо отлажены. Так же ресурс «Reports and Data» прогнозирует объем рынка анализа рисков к 2026 в объеме
Посерфил обнаружил в сети, что существует всего лишь один университет, у которого есть программа обучения по данному курсу в The Hong Kong University of Science and Technology и нижепредставленную статью. После таких результатов мне стало ясно, что тема исследована слабо и причина в том, что риск-менеджмент отдельное направление с достаточно широким диапазоном и риски в операционной деятельности предприятия — подраздел этих мероприятий.
Чтобы читатель мог представить широту задач даю ссылку на статью об инструментах в этой области «The 19 Best Risk Management Software of 2021».
После переведенной статьи изложил свои размышления о том, как сделать набор бизнес-метрик инструментом риск-менеджмента.